Anthropic Unveils Claude Opus 4.7: A Smarter, Safer AI Model
Anthropic has officially launched Claude Opus 4.7, its most capable commercially available AI model to date, and it comes packed with significant upgrades across coding, vision, and developer tooling.

A Major Step Up in Software Engineering
The new model represents a meaningful upgrade to Anthropic's flagship AI, with better coding performance, sharper vision capabilities, and a new ability to verify its own outputs before delivering results. Axios Users who previously had to supervise Claude on difficult engineering tasks closely can now hand off that work with greater confidence.
Score on an internal agentic coding evaluation as a function of token usage at each effort level. In this evaluation, the model works autonomously from a single user prompt, and results may not be representative of token usage in interactive coding. See the migration guide for more on tuning effort levels.
Dramatically Improved Vision
On the vision side, Opus 4.7 processes images at resolutions up to 2,576 pixels on the long edge, more than three times the capacity of prior Claude models. Rolling Out. This opens up a much wider range of applications for users working with detailed diagrams, technical documents, and high-resolution visual content.

Honest About Its Limits
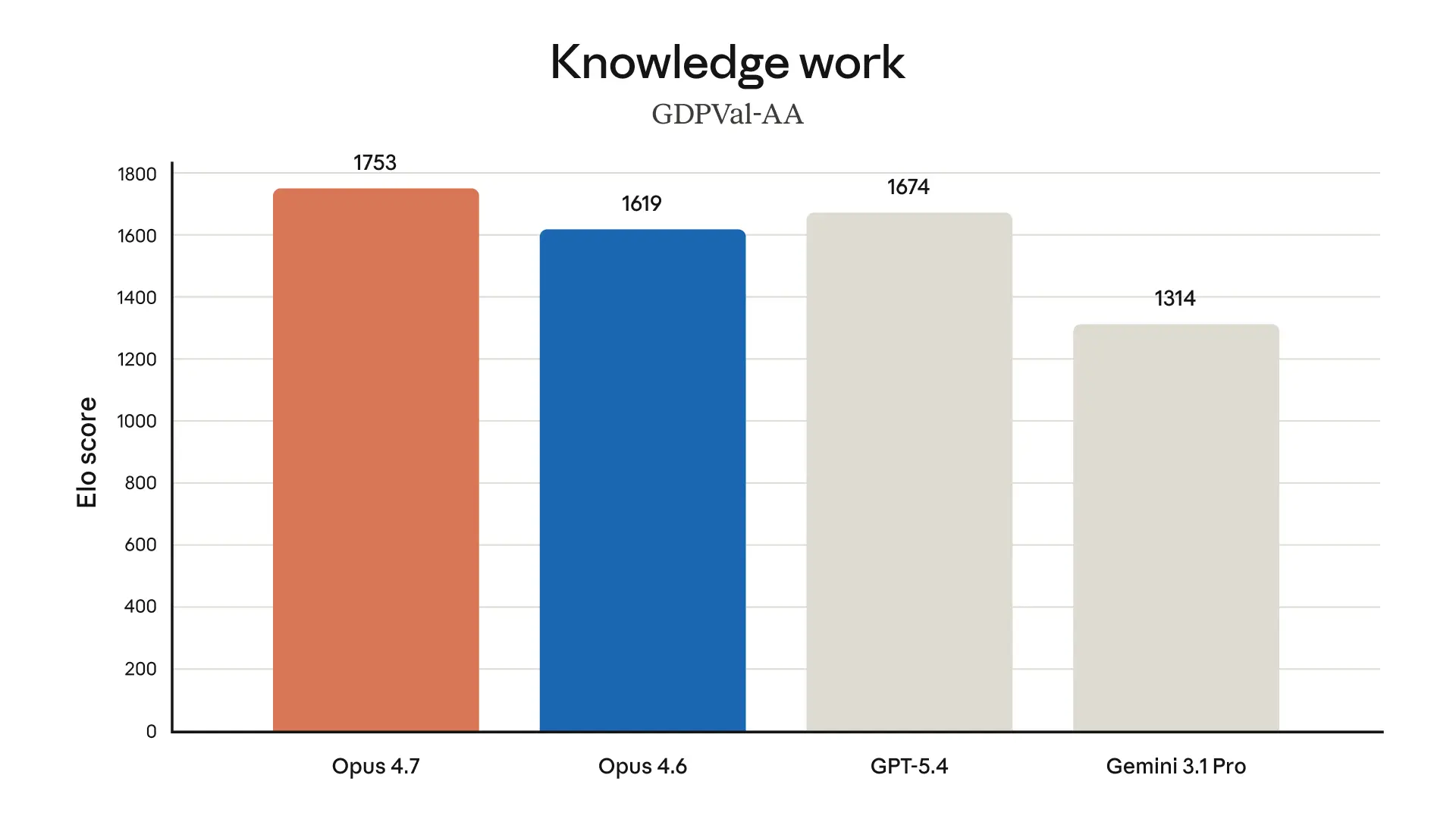
Anthropic publicly acknowledged that Opus 4.7 does not match the performance of Mythos Preview, its most powerful model, which has only been released to a select group of tech and cybersecurity companies due to safety concerns. Axios. That said, benchmarks show Opus 4.7 outperforming both Claude Opus 4.6 and rivals like GPT-5.4 and Gemini 3.1 Pro across several key categories.

Overall misaligned behavior score from our automated behavioral audit. On this evaluation, Opus 4.7 is a modest improvement on Opus 4.6 and Sonnet 4.6, but Mythos Preview still shows the lowest rates of misaligned behavior.
Built With Cybersecurity in Mind
Anthropic experimented with reducing Opus 4.7's cyber capabilities during training and is releasing the model with safeguards that automatically detect and block requests associated with prohibited or high-risk cybersecurity uses. CNBC Security professionals with legitimate needs can apply through Anthropic's new Cyber Verification Program.
New Tools for Developers
A new effort level called "xhigh" has been introduced, sitting between the existing high and max settings, giving users more granular control over the tradeoff between reasoning depth and response speed. Task budgets are also now available in public beta for API users, and a new ultrareview command has been added to Claude Code for bug detection. Rolling Out
Availability and Pricing
Claude Opus 4.7 is available across all of Anthropic's Claude products, its API, and through cloud providers Microsoft, Google, and Amazon, at the same price as Opus 4.6.
Footnotes
1 This is a model-level change rather than an API parameter, so images users send to Claude will simply be processed at higher fidelity. Because higher-resolution images consume more tokens, users who don’t require the extra detail can downsample images before sending them to the model.
For GPT-5.4 and Gemini 3.1 Pro, we compared against the best reported model version available via API in the charts and table.MCP-Atlas: The Opus 4.6 score has been updated to reflect revised grading methodology from Scale AI.SWE-bench Verified, Pro, and Multilingual: Our memorization screens flag a subset of problems in these SWE-bench evals. Excluding any problems that show signs of memorization, Opus 4.7’s margin of improvement over Opus 4.6 holds.Terminal-Bench 2.0: We used the Terminus-2 harness with thinking disabled. All experiments used 1× guaranteed/3× ceiling resource allocation averaged over five attempts per task.CyberGym: Opus 4.6’s score has been updated from the originally reported 66.6 to 73.8, as we updated our harness parameters to better elicit cyber capability.SWE-bench Multimodal: We used an internal implementation for both Opus 4.7 and Opus 4.6. Scores are not directly comparable to public leaderboard scores.